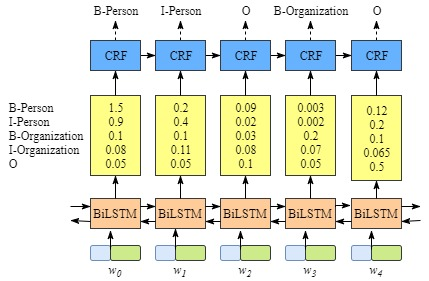
The example below implements the forward algorithm in log space to compute the partition function, and the viterbi algorithm to decode. Backpropagation will compute the gradients automatically for us. We don’t have to do anything by hand.
The implementation is not optimized. If you understand what is going on, you’ll probably quickly see that iterating over the next tag in the forward algorithm could probably be done in one big operation. I wanted to code to be more readable. If you want to make the relevant change,you could probably use this tagger for real tasks.
1 2 3 4 5 6 7 8
# Author: Robert Guthrie
import torch import torch.autograd as autograd import torch.nn as nn import torch.optim as optim
# 转移矩阵,Matrix of transition parameters. Entry i,j is the score of # transitioning *from* j *to* i self.transitions = nn.Parameter( torch.randn(self.tagset_size, self.tagset_size))
# 计算loss的第一项(分母项),也就是需要计算所有路径的总分数的log def_forward_alg(self, feats): #feats表示发射矩阵(emit score),实际上就是LSTM的输出,意思是经过LSTM的sentence的每个word对应于每个label的得分 # Do the forward algorithm to compute the partition function() # 用-10000.来填充一个形状为[1,tagset_size]的tensor init_alphas = torch.full((1, self.tagset_size), -10000.) # 因为start tag是4,所以tensor([[-10000., -10000., -10000., 0., -10000.]]), # 将start的值设零,表示开始进行网络的传播, # START_TAG has all of the score. init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# Wrap in a variable so that we will get automatic backprop forward_var = init_alphas # 初始状态的forward_var,随着step t变化
# Iterate through the sentence for feat in feats: alphas_t = [] # The forward tensors at this timestep for next_tag inrange(self.tagset_size): # broadcast the emission score: it is the same regardless of # the previous tag # LSTM的生成矩阵是emit_score,维度为1*5 emit_score = feat[next_tag].view( 1, -1).expand(1, self.tagset_size) # the ith entry of trans_score is the score of transitioning to # next_tag from i trans_score = self.transitions[next_tag].view(1, -1) # The ith entry of next_tag_var is the value for the # edge (i -> next_tag) before we do log-sum-exp # 对于到词$w_i$的路径,以先把到词$w_{i-1}$的logsumexp计算出来,再加上当前tag产生的分数 next_tag_var = forward_var + trans_score + emit_score alphas_t.append(log_sum_exp(next_tag_var).view(1)) forward_var = torch.cat(alphas_t).view(1, -1) # 最后还需要加上最后一个词转移到结束位置的概率 terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]] alpha = log_sum_exp(terminal_var) return alpha
# Initialize the viterbi variables in log space init_vvars = torch.full((1, self.tagset_size), -10000.) # 保证了一定是从START到其他标签 init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var at step i holds the viterbi variables for step i-1 forward_var = init_vvars for feat in feats: bptrs_t = [] # holds the backpointers for this step viterbivars_t = [] # holds the viterbi variables for this step
for next_tag inrange(self.tagset_size): # next_tag_var[i] holds the viterbi variable for tag i at the # previous step, plus the score of transitioning # from tag i to next_tag. # We don't include the emission scores here because the max # does not depend on them (we add them in below) next_tag_var = forward_var + self.transitions[next_tag] #forward_var保存的是之前的最优路径的值 best_tag_id = argmax(next_tag_var) #返回最大值对应的那个tag的id bptrs_t.append(best_tag_id) viterbivars_t.append(next_tag_var[0][best_tag_id].view(1)) # Now add in the emission scores, and assign forward_var to the set # of viterbi variables we just computed forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1) backpointers.append(bptrs_t)
# Follow the back pointers to decode the best path. # 从最后一步的best_path的选择,根据backpointers倒推整个的best_path best_path = [best_tag_id] for bptrs_t inreversed(backpointers): best_tag_id = bptrs_t[best_tag_id] best_path.append(best_tag_id) # Pop off the start tag (we dont want to return that to the caller) start = best_path.pop() assert start == self.tag_to_ix[START_TAG] # Sanity check best_path.reverse() return path_score, best_path
# 计算一个句子的分数和最优的标注序列,预测时候用 defforward(self, sentence): # dont confuse this with _forward_alg above. # Get the emission scores from the BiLSTM lstm_feats = self._get_lstm_features(sentence)
# Find the best path, given the features. score, tag_seq = self._viterbi_decode(lstm_feats) return score, tag_seq
# Make up some training data training_data = [( "the wall street journal reported today that apple corporation made money".split(), "B I I I O O O B I O O".split() ), ( "georgia tech is a university in georgia".split(), "B I O O O O B".split() )]
# 构造训练数据中的word_to_ix的映射关系,给每一个词对应一个唯一的编码 # 比如‘HELLO WORLD’就是{'HELLO':0,'WORLD:1'} word_to_ix = {} for sentence, tags in training_data: for word in sentence: if word notin word_to_ix: word_to_ix[word] = len(word_to_ix)
# Check predictions before training with torch.no_grad(): precheck_sent = prepare_sequence(training_data[0][0], word_to_ix) precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long) print(model(precheck_sent))
# Make sure prepare_sequence from earlier in the LSTM section is loaded for epoch inrange( 300): # again, normally you would NOT do 300 epochs, it is toy data for sentence, tags in training_data: # Step 1. 一定要记住Pytorch会累积梯度 # 所以我们在每个样本训练之前需要清除梯度 model.zero_grad()
# Step 2. 准备模型的输入,把输入的样本数据转化为模型需要的格式 # 把输入的词序列和标签转化为id,再把id转化为Tensor sentence_in = prepare_sequence(sentence, word_to_ix) targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. 让模型前向传播计算Loss loss = model.neg_log_likelihood(sentence_in, targets)
# Check predictions after training with torch.no_grad(): precheck_sent = prepare_sequence(training_data[0][0], word_to_ix) print(model(precheck_sent)) # We got it!